Why your choice of variable names can slow down your program - a deep dive into Python
Have you ever wondered if the names you give your variables affect the performance of your program?
For the vast majority of programming languages, this should have no measurable impact, at least not on the runtime performance.
However, when it comes to Python, even experienced developers may struggle to give a clear answer to this question, because there are indeed reasons to believe that the variable names can sabotage performance.
It is therefore not surprising that others have already addressed this question, for example in this article or on stackoverflow.
They all found that very long variable names can slow down your Python program.
Fortunately, this only happens when the variable names become extremely long, otherwise the slowdown is
only marginal.
The reason I am still writing this article is that all the other articles or posts have only dealt with “normal” global and local variables.
In this article, we will revisit this question for a special type of variable, the class attribute.
If you are interested in the solution to this question but not the way to get there, you can read only the highlighted sections and the conclusion at the very end.
Class attributes
A class attribute is a variable that is bound directly to a class and not to an instance of that class.
A variable that belongs to an instance is called an instance attribute.
Class attributes are shared among all instances of that class, and when the value of such variable changes, this is reflected in all instances.
Changing an instance attribute does not affect the class or other instances of the class.
The reason that I am pointing this out is that Python internally treats class and instance attributes very differently.
An example of a class with a class attribute would be:
class MyBlog:
post = 'Hello world!'
myblog = MyBlog()
We can access the post attribute directly from the class itself using MyBlog.post, or we can first create an instance of the class and access it like myblog.post.
In both cases, we are accessing the shared class attribute and yet these cases are handled quite differently internally.
However, because the conclustion of this article would be similar in both cases, we look at the simpler case, the access on the class.
We may look at the class attribute lookup on the instance in a future blog post.lookup two attributes
Attribute lookup time
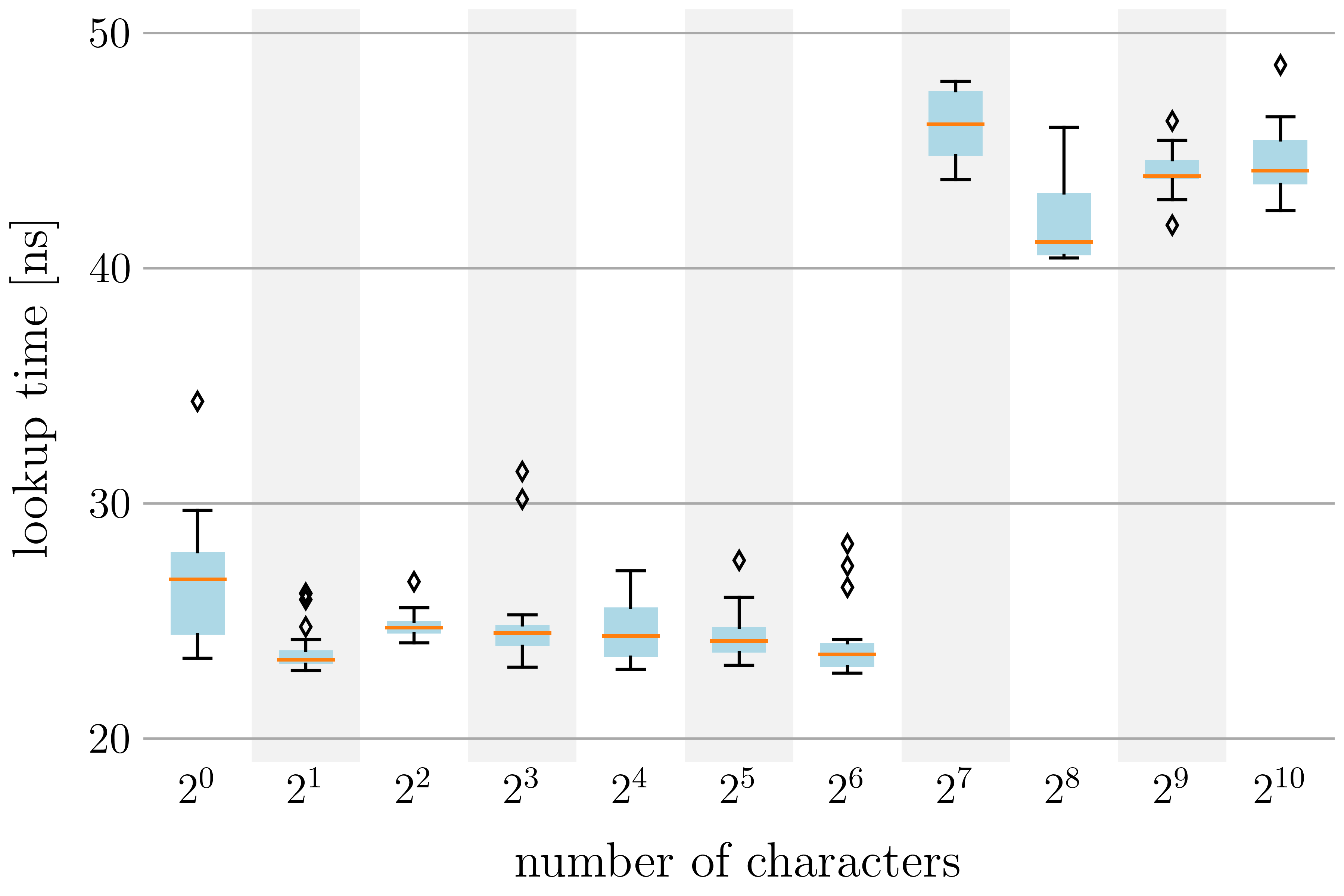
Looking up the attribute post from our previously defined class takes a bit more than 20 ns on my notebook.
What do you think, can this time be shortened or lengthened by giving the attribute a different name, e.g. longer or shorter?
This is precisely what I have tested for different attribute names, from 1 character long names to 1’024 character long names.
The results are shown in the figure below.
We see a clear discontinuity from 64 to 128 characters, where the lookup time almost doubles from about 25 ns to 45 ns.
This is already a very interesting observation and was very unexpected for me. If you are as surprised as I was, then I would like to pique your curiosity even more.
In this article, we will see that sometimes, even if the length of our class attribute names are shorter than 64 characters, we may still have to spend 45 ns on the lookup.
CPython
To understand why we end up being penalized for our choice of attribute names, we need to take a look at how Python implements types, more specifically, how CPython 3.11 implements types.
Mentioning the Python implementation is necessary because other Python implementations[1] and older CPython versions behave differently.
You can find the Python repository I refer to here on Github.
If you are new to Python, you can ignore this disclaimer as CPython is by far the most popular distribution and you are most likely already using a recent version of it.
How attributes are looked up
The decimated code shown below is part of the official, recently released CPython 3.11 distribution.
It shows how Python looks up attributes of types. Note that the terms class and type are essentially unified in Python so I use them interchangeably.
The function type_getattro is called whenever we look up a class attribute such as MyBlog.post.
The function takes two arguments, the first one PyTypeObject *type is the type that implements the attribute, which is our MyBlog class.
The second argument PyObject *name is the name of the attribute we want to retrieve, in our case the variable post.
We see that every time we look up an attribute, Python first looks for it in the type’s metatype[2] before checking the type itself.
In both cases, however, _PyType_Lookup is called, which implements the actual attribute lookup.
// cpython/Objects/typeobject.c (lino 4258)
static PyObject *
type_getattro(PyTypeObject *type, PyObject *name)
{
...
/* Look for the attribute in the metatype */
meta_attribute = _PyType_Lookup(metatype, name);
...
/* No data descriptor found on metatype. Look in tp_dict of this
* type and its bases */
attribute = _PyType_Lookup(type, name);
...
}
The following code shows parts of the _PyType_Lookup implementation.
These three lines of code in the function body already give us a lot of information about what might have caused the doubling of the lookup time when the attribute name is long. Or should I say the halving when the attribute name is short?
// cpython/Objects/typeobject.c (lino 4176)
PyObject *
_PyType_Lookup(PyTypeObject *type, PyObject *name)
{
...
// Try to fish the attribute out of the cache
unsigned int h = MCACHE_HASH_METHOD(type, name);
struct type_cache *cache = get_type_cache();
struct type_cache_entry *entry = &cache->hashtable[h];
...
}
The function _PyType_Lookup first uses the macro MCACHE_HASH_METHOD with the type and name as arguments to get an integer h.
Next, it gets a pointer to a type_cache variable named cache by calling get_type_cache().
If you are familiar with hashing and caching, you may already guess where this is going.
In a third step, it accesses an array hashtable at the index h to obtain a pointer to a type_cache_entry variable named entry.
To understand what is going on, we need to know a few basics about caching and hashing.
- A cache is a data/information storage.
Access to it is usually implemented to be fast because the data is used frequently. Alternatively,
it contains data that would be expensive to recompute.
- Hashing describes the mapping of an input of arbitrary size to an output of restricted size.
Hash functions also have many other very important properties, such as that there is no inverse function or that two different inputs must not give the same output (ideally).
This is extremely important in cryptography, or you may have heard of it in the context of Bitcoin.
For us, however, only the first point is important.
Let’s use this information to draw an intermediate conclusion. We just found out that the class attributes may be cached and that the hash which is a combination of the type/class and attribute name is the location at which the attribute value is stored.
We can even conclude that the generated hash value must be within a bounded range. It must not exceed the array/cache bounds.
Otherwise, it would be unsafe because it eventually leads to bad memory access.
Type cache and hash function
Let’s go a step further and see how Python implements this type-cache and hash function. The relevant code is shown below.
// cpython/Objects/typeobject.c (lino 34)
#define MCACHE_SIZE_EXP 12 // cpython/Include/internal/pycore_typeobject.h (lino 29)
#define MCACHE_MAX_ATTR_SIZE 100
#define MCACHE_HASH(version, name_hash) \
(((unsigned int)(version) ^ (unsigned int)(name_hash)) & ((1 << MCACHE_SIZE_EXP) - 1))
#define MCACHE_HASH_METHOD(type, name) \
MCACHE_HASH((type)->tp_version_tag, ((Py_ssize_t)(name)) >> 3)
#define MCACHE_CACHEABLE_NAME(name) \
PyUnicode_CheckExact(name) && \
PyUnicode_IS_READY(name) && \
(PyUnicode_GET_LENGTH(name) <= MCACHE_MAX_ATTR_SIZE)
We see that Python defines a macro MCACHE_SIZE_EXP as 12.
This number is the cache size or more specifically, its logarithm. The actual cache size is 4’096. This will become important later.
Python also defines a macro MCACHE_MAX_ATTR_SIZE as 100, which is the value used in the macro MCACHE_CACHEABLE_NAME.
MCACHE_CACHEABLE_NAME checks whether an attribute should be cached or not.
The important to us criterion to decide this is that PyUnicode_GET_LENGTH(name) <= MCACHE_MAX_ATTR_SIZE. In Python this reads len(name) <= 100.
So the attribute can only be cached if its name is no longer than 100 characters.
And with this, we have found a hard threshold where the attribute lookup time increases because it is no longer possible to cache the attribute.
Slow lookup on short names
Remember when I told you at the beginning that a short variable name is no guarantee that the lookup will be fast?
If we go back to _PyType_Lookup and look at another part of the function (see code below), we find that if the attribute is not found in the cache, Python uses the macro MCACHE_CACHEABLE_NAME to check if it can be cached for the future. If the answer is yes, the attribute is added to the cache.
Note that assign_version_tag checks if type is a valid Python object and has a tp_version_tag field. The tp_version_tag field is the actual type information used to compute the hash in MCACHE_HASH (code above).
// cpython/Objects/typeobject.c (lino 4176)
PyObject *
_PyType_Lookup(PyTypeObject *type, PyObject *name)
{
...
// Include the attribute in the cache if certain conditions are met
if (MCACHE_CACHEABLE_NAME(name) && assign_version_tag(type)) {
h = MCACHE_HASH_METHOD(type, name);
struct type_cache_entry *entry = &cache->hashtable[h];
entry->version = type->tp_version_tag;
entry->value = res; /* borrowed */
...
}
...
}
The problem is that the cache can store a maximum of 4’096 elements, as we found out, and the hash function must return a value between 0 and 4’096-1, or otherwise our program might crash.
Also, Python does not check if a slot in the cache is already occupied, but always inserts the element if two very general criteria are met. Note, however, that Python checks the entry when it fetches it from the cache to avoid returning incorrect values.
So, if we have more than 4’096 class attributes, some of them will certainly throw each other out of the cache and get reinserted whenever they are accessed. I would also like to highlight that this cache is shared among all types/classes. There is no separate cache for each class.
This is not a big deal in most cases since we usually don’t have that many attributes.
But even if we had many class attributes, we would still have to look them all up frequently to have them compete for the cache.
However, there is one scenario we can’t control that leads to slow attribute lookup with short names, even in realistic use cases.
Since the hash function must return the cache index — the hash — from an arbitrarily long string — the attribute name —, so-called hash collisions are not entirely unlikely. A hash collision occurs when different combinations of type and attribute names return the same hash.
Since the space of possible hashes is small (at maximum 4’096 different values), it is likely that this has happened to you in the past already.
In this scenario, the attribute lookup becomes slow even if as few as two class attributes are actively used.
Forcing hash collisions
To demonstrate this concept of a hash collision, I wrote a small C extension module[3] with a function compute_hash that takes a Python type and attribute name in the form of a Python string and returns the corresponding hash using Python’s own hash function MCACHE_HASH_METHOD.
The hash is returned as a Python integer.
static PyObject *compute_hash(PyObject *self, PyObject *args)
{
PyTypeObject *type = PyTuple_GetItem(args, 0);
PyObject *name = PyTuple_GetItem(args, 1);
unsigned int h = MCACHE_HASH_METHOD(type, name);
return PyLong_FromLong((long)h);
}
At this point, I want to inform you that you can find all the codes for this article in my Github repository.
There you will also find a short README.md that explains how to build the extension module to use it in Python.
Of course, you can also find all the other codes used for this article there to check and test things yourself.
Don’t forget to use CPython 3.11 as there was a recent change in the MCACHE_HASH_METHOD macro!
We can now use compute_hash of our hashmod module in Python to compute hashes for a given type and string.
We are interested in hash collisions. Since the possible number of hashes is small, brute force is our way to go.
We first create as many attribute names as the cache is large, plus one more.
Then, for each of the names and the class MyBlog, we compute the corresponding hash.
This way we can guarantee that we obtain at least one pair of names with identical hashes.
We find a name with the most frequent hash using the Counter from the built-in collections module. We call this name our reference name name_ref.
We then find another different name with the identical hash, which we call the colliding name name_coll. We also choose a name with a non-colliding hash name_noncoll.
Finally, we assign three attributes with exactly these three names to the MyBlog class.
from collections import Counter
from hashmod import compute_hash
class MyBlog:
...
# Generate `cache_size + 1` names
MCACHE_SIZE_EXP = 12
attr_names = [f'post{i}' for i in range((1 << MCACHE_SIZE_EXP) + 1)]
hash_list = [compute_hash(MyBlog, name) for name in attr_names]
hash_counts = Counter(hash_list).most_common()
# most frequent hash `h0`
h0 = hash_counts[0][0]
idx = hash_list.index(h0)
# reference name resulting in `h0`
name_ref = attr_names[idx]
# colliding name also resulting in `h0`
idx = hash_list.index(h0, idx+1)
name_coll = attr_names[idx]
# another hash `h1 != h0`
h1 = hash_counts[1][0]
idx = hash_list.index(h1)
# name with non-colliding hash `h1`
name_noncoll = attr_names[idx]
# assign attributes with our three names to the class
for name in (name_ref, name_coll, name_noncoll):
setattr(MyBlog, name, "Glad that you're still with me!")
When alternately accessing name_ref and name_coll, we expect performance degradation, because when looking up one of the attributes, the other one gets evicted from the cache, only to be reinserted on the next lookup.
If the attribute is not found in the cache, we have to pay for the slow lookup and reinsertion.
On the other hand, we do not expect any performance penalty if we do the same with name_ref and name_noncoll.
Both attributes are cached on the first lookup and retrieved from the cache on subsequent lookups.
Both scenarios are shown below.
stmt_collision = f"""
MyBlog.{name_ref}
MyBlog.{name_coll}
"""
stmt_no_collision = f"""
MyBlog.{name_ref}
MyBlog.{name_noncoll}
"""
We now execute each of the two statements 1’000’000 times and repeat this process 20 times.
The built-in time and timeit modules provide convenient functions for this.
Then the average time per attribute lookup is calculated for either scenario.
import timeit
from time import perf_counter_ns
kwargs = dict(
timer=perf_counter_ns,
repeat=20,
number=1_000_000,
globals=dict(MyBlog=MyBlog)
)
for stmt in (stmt_collision, stmt_no_collision):
timings = timeit.repeat(stmt, **kwargs)
# average lookup time per attribute (we lookup two attributes)
avg_time = sum(timings) / len(timings) / kwargs['number'] / 2
print(f'{avg_time:.2f} ns')
>> 51.93 ns
>> 21.34 ns
On my computer, the lookup for colliding names takes 52 ns, while for non-colliding names it takes only 21 ns.
This is, of course, exactly what we expected.
Conclusion
To wrap things up, let’s list the most important findings:
- Class attributes with names longer than 100 characters are stored in a globally shared cache among all classes to speed up attribute lookups.
- This cache can store up to 4’096 values. The index at which the attribute is stored depends on its owner class and its name, and is computed using a hash function.
- Since the cache is relatively small, hash collisions may occur. In such cases, Python goes through a slow attribute lookup even for short attribute names because they are constantly competing for the same slot in the cache.
I hope you enjoyed this walk through the depths of Python and that I may have sparked your interest in Python. I can only suggest that you take a look at the Python repository yourself. It’s well structured and written in such a way that even with moderate programming experience you can guess some of what’s going on under the hood. There is a lot to discover!
Before I end this blog post, I want to clarify that this article is for entertainment and educational purposes only. I am not asking you to consider attribute names as performance relevant. Give your attributes the most descriptive names, not the fastest[4].
Thanks for reading and see you in the next one!
[1]: Other well-known Python distributions are e.g. IronPython, PyPy or Jython.
[2]: You can read about metatypes/metaclasses here.
[3]: A C extension is C code exposed to Python so that it behaves like a built-in Python module.
[4]: Intentionally avoiding hash collisions is also a bad idea since even small changes in your program can cause the same names to either not collide or suddenly collide.
For example, the tp_version_tag is an identifier that depends on what other classes are defined.